Natural language processing (NLP)
NLP is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyse large amounts of natural language data (Wikipedia). It is also a super set to text analytics.
DMR uses NLP to annotate text in any language with sentiment, topics, customer journey stage, demographics of author etc.
The main ways DMR uses to process, understand and generate language using a computer are:
- Rules based including the use of dictionaries and regular expressions (regex)
- Statistical methods i.e. machine learning
- Neural networks – Deep learning
The DMR preferred and more accurate approaches are machine learning and deep learning – which is how artificial intelligence (AI) is produced – because with the right training data set a custom machine learning model can be created that does a certain job (such as predict sentiment or topics) very efficiently and accurately. Its main benefit over a rules-based approach is that it can infer answers, it is not limited to the set of rules or words the user can think of at the time of rule creation.
Natural language can be expressed in audio, text and sometimes other visual cues such as symbols that represent language.
The DMR listening247 platform can ingest and annotate (using custom AI to add intelligence):
- text
- audio files that are automatically transcribed to text (voice-to -text)
- images that are automatically captioned (image-to-text)
Text Analytics
Text analytics is a subset of NLP along with audio, symbols etc. Text is considered a form of unstructured data. With text analytics millions of documents (calls, chats or online posts etc.) can be turned into structured data visualised on drilldown dashboards or PPT reports and presentations.
DMR has implemented automated ways to turn other forms of language such as audio and images to text so that it can be ingested on listening247 and annotated using custom taxonomy elements (rules based), machine learning and deep learning models.
The DMR text analytics solution distills unstructured data in any language to a size that a human can process. In other words it turns unstructured data to structured which can be numbers in tables or a drill-down dashboard. Unstructured data can be in the form of text, audio, images and video.
Below is a list unstructured data sources that are regularly ingested on listening247 for analytics:
- social media posts
- other public online sources such as news, blogs, forums and reviews
- call center call transcripts
- private chat messages
- emails
- focus group transcripts
- answers to survey open ended questions
You will find more information around the analytics of social media and other online posts under Social Intelligence. Similarly you will find more information around analytics of calls, chats and emails under CX Management. The content of this page - “Text Analytics” - refers to any use case other than the aforementioned ones that requires machine learning to add intelligence and subsequently analyse text from any source – even a book.
Here is a list of intelligence that DMR can accurately add to text from any source and in any language:
- Sentiment
- Emotions (proprietary model for 7 pairs of opposite emotions)
- Topics – subtopics – attributes
- Reason for contact
- Customer Journey stage
- Author/Customer Age
- Diarisation – who is the speaker in an audio conversation
- Adverse effects
Annotation Accuracy
Accuracy is an umbrella term used for simplicity. The true terms are precision, recall and F1-score. Here is a simple Wikipedia definition: “In simple terms, high precision means that an algorithm returned substantially more relevant results than irrelevant, while high recall means that an algorithm returned most of the relevant results.” Another more detailed definition provided on Wikipedia is this:
“In a classification task, the precision for a class is the number of true positives (i.e. the number of items correctly labelled (by the algorithm) as belonging to the positive class) divided by the total number of elements labelled (by the algorithm) as belonging to the positive class (i.e. the sum of true positives and false positives - which are items incorrectly labelled as belonging to the class). Recall, in this context, is defined as the number of true positives divided by the total number of elements that actually belong to the positive class (i.e. the sum of true positives and false negatives - which are items that were not labelled as belonging to the positive class but should have been).”
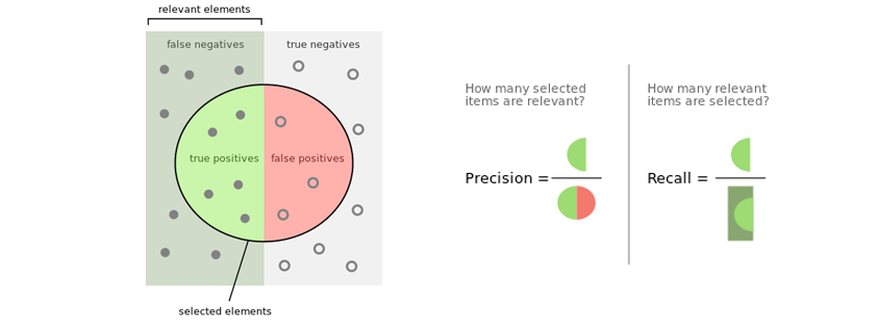
Image source: By Walber (Own work) [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], via Wikimedia Commons
As an example, 80% sentiment accuracy means: if you are given 100 documents that are annotated with positive, negative or neutral sentiment by a machine, you will agree with 80 of them and disagree with 20.
OR
80% sentiment accuracy means: if you are given 100 positive verbatims or documents from any source about your subject, only 80 will be positive; the rest will be negative, neutral or irrelevant.
100% sentiment accuracy of online posts, for example, is not attainable because even humans do not agree among themselves. In 10-30% of the cases there may be a lack of consensus on whether an online post is positive, negative or neutral. If we can accept that ambiguity will always exist, due to sarcasm and other complex forms of expression, then how do we expect a machine learning algorithm to agree with all the humans checking the data?
The most popular way to check sentiment accuracy is to extract a random sample of 100-1000 verbatims or documents and have 2-3 humans manually annotate them with sentiment. We then compare the sentiment that the algorithm has assigned to each of the docs and determine the percent agreement between all 3 human curators and the algorithm.
Precision and recall are not only relevant for measuring sentiment accuracy but also we can use them to measure semantic accuracy i.e. how accurately a solution can report topics and themes of online conversations or any other intelligence type that can be added to text using AI.
Text mining
Text mining, also referred to as text data mining, like text analytics, is the process of deriving high-quality information from text or just collecting/gathering/harvesting text for the purpose to analyse and understand it’s content. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources. Written resources may include websites, books, emails, reviews, and articles. (Wikipedia).
Image analytics
“A picture is worth a thousand words” is an old adage that holds true today just as it did in 1911 when it was coined. Perhaps even more so today as according to Twitter: 77% of all tweets about soft drinks do not include any textual reference to this subject; an image makes whatever point the author wants to make instead.
There are over 1,000 social media monitoring tools out there which use text analytics to analyse social media posts; if the soft drink statistic above is true for all products, then these tools are failing their users - the marketing professionals.
DMR was lucky enough to be the recipient of a grant from Innovate UK that allowed some of its team members to focus on R&D for 16 months and produce a solution - "DEEPTHEME" - to this obvious gap in the market of social media listening and analytics; a neural network with tens of layers that takes pixels as input and produces a caption in the form of a proper sentence, essentially describing what an image is about. I will be a pompous "a.." and say that object recognition (e.g. a brand logo) is fairly easy compared to the degree of difficulty of using "Deep Learning" (=neural networks with more than 4 layers) to produce a sentence that makes sense with pixels as the only input; this is the type of AI that brings us closer to Strong AI (Strong AI's goal is to develop artificial intelligence to the point where the machine's intellectual capability is functionally equal to a human's. Berkeley.edu)
I will outline the most common market research use case in some detail using a hypothetical scenario:
- we harvested 20 million posts about a product category from the past 12 months in Mandarin in order to carry out sentiment and semantic analysis and enhance a brand health tracking survey that a blue chip multinational runs in China. The monthly tracker includes 1000 survey responses every month.
- in the 20 million posts from multiple social media and other public websites including reviews on e-commerce sites, there are about 10 million images.
- a regular text analytics tool would only be able to analyse the text in the posts - assuming it can analyse Mandarin in the first place - and would deliver a report in the form of a dashboard with a questionable accuracy (not many marketers think to ask the question: what is your tool's sentiment and semantic accuracy? They end up with less than 50% accuracy)
- in the 10 million posts with text they discover that the discussion drivers are price and customer service complaints. Had they been able to analyse the 10 million images as well they would discover that product users like to show off the product while they are having fun with friends, on vacation and generally during their social time.
Thankfully DEEPTHEME produced the Magic Captioner which turns images to full sentences about the occasion of product usage. These sentences can be analysed for topics, sub-topics and attributes of conversations like any other post with text. The probability to discover valuable customer insights is now at least double, if not more. It is still a young A.I. and it appreciates any education you can provide as it trains itself based on user feedback.
DMR can help:
- Increase your Revenue by helping you create better products for your customers
- Reduce your Cost by leveraging the internet, community panels, the social web
- Reduce or Eliminate your Risk to fail with your marketing investment
- Make your lives Easier by providing you with actionable business insights that will make success look like a walk in the park!
